
Dynamic Topic Modelling Methodology

Image Source: Image by Thomas Kelley on Unsplash
Overview of topic modelling
It is a challenge for humans to read tens of thousands of documents and identify common themes and track trends throughout. A commonly used data science solution to overcome this challenge is topic modelling. Topic modelling is a Natural Language Processing technique that identifies clusters of words in a set of documents. These clusters of words are assumed to represent topics in the underlying text. Many topic models do not make considerations for analysing topics in an evolving text corpus; the models focus on modelling a static dataset and there are multiple challenges when a dynamic dataset is used.
In this blog, we present our method for performing topic modelling with a dynamic element. The dynamic focus of our work enables the use of topic models for ongoing analysis of text data that grows over time. We initially applied the method to a large corpus of roughly 40,000 documents that grows by approximately 1,000 documents per month. We provide example results using an open dataset in this blog. The result of our method is a model that is able to track topics over time. This is of benefit as topics that grow more popular, less popular or change can be labelled manually as evolving, receding, emerging or persistent topics. The identification of changes to topics can then be used to help make informed business decisions in response to those changes.
Aims
This paper will focus on our modelling strategy, which we present as dynamic topic modelling. We will:
- illustrate the problems we found when using traditional topic models with text data that grows
- briefly outline the preprocessing steps we apply to text data before using it to inform a model
- provide our method for performing dynamic topic modelling
- discuss the results we have found
- share the limitations and present opportunities for future work
Traditional topic models
A traditional topic model, for example Latent Dirichlet Allocation (LDA), takes a vectorised text dataset as input and returns distributions of words over topics and topics over documents. With these distributions we are able to find which words contribute significantly to a topic and which topics contribute significantly to a document. The initialisation of a topic model involves randomly assigning each word in the documents to a random topic. As a result of this randomness the outputs may vary between model run times:
- The LDA process is initialised from a random starting point so there is no guarantee (excluding the use of random seeds) that the same topics will be found when performing LDA on the same dataset twice
- The randomness also produces a problem in that topics may not be listed in the same order this makes linking topics from two models a challenge
These problems are further amplified when the underlying text changes, even when these changes are small. For example, consider performing LDA on a corpus of three thousand documents, then on a corpus of the same three thousand plus an extra one thousand documents. Even if we use the same random seed and number of topics as hyperparameters the list of topics returned will tend to differ in order and representation of the topics even when the topics are the same semantically.
Table 1: The problems of traditional topic models

In the example above when performing an analysis of these topics it is difficult to see that Period 1 topic 1 and Period 2 topic 3 are likely to be the same topic. Further, when performing topic modelling at scale with a large number of topics this issue is amplified, making it hard to label topics as emerging, persistent or receding through time. Even in cases where the same word lists appear at the same index the topic they represent may be slightly different in terms of the underlying word distribution.
We note that approaches to performing topic modelling with temporal data do exist in the literature, Dynamic LDA being one example. However, these approaches focus on a single static corpus with a temporal element attached retrospectively. The problem we aim to address is performing topic modelling on one dataset at a given time point, then adding to that data (and in all likelihood changing the underlying word distributions), creating a second model and assessing how topics have changed.
Preparing text data for topic modelling
We apply standard text cleaning approaches to the text data used by our model:
- tokenisation
- lemmatisation
- stop word removal
We then apply a Term Frequency-Inverse Document Frequency (TF-IDF) vectorisation to the text data. TF-IDF vectors represent each document as a series of numbers based on the use of the words within and between documents. Words that are used commonly throughout all documents are weighted with low values, as are words that are rarely used. Words that are used commonly in a subset of documents are weighted highly. This is why TF-IDF is commonly used in topic modelling as words commonly used in a subset of documents likely represent topics.
Dynamic topic modelling
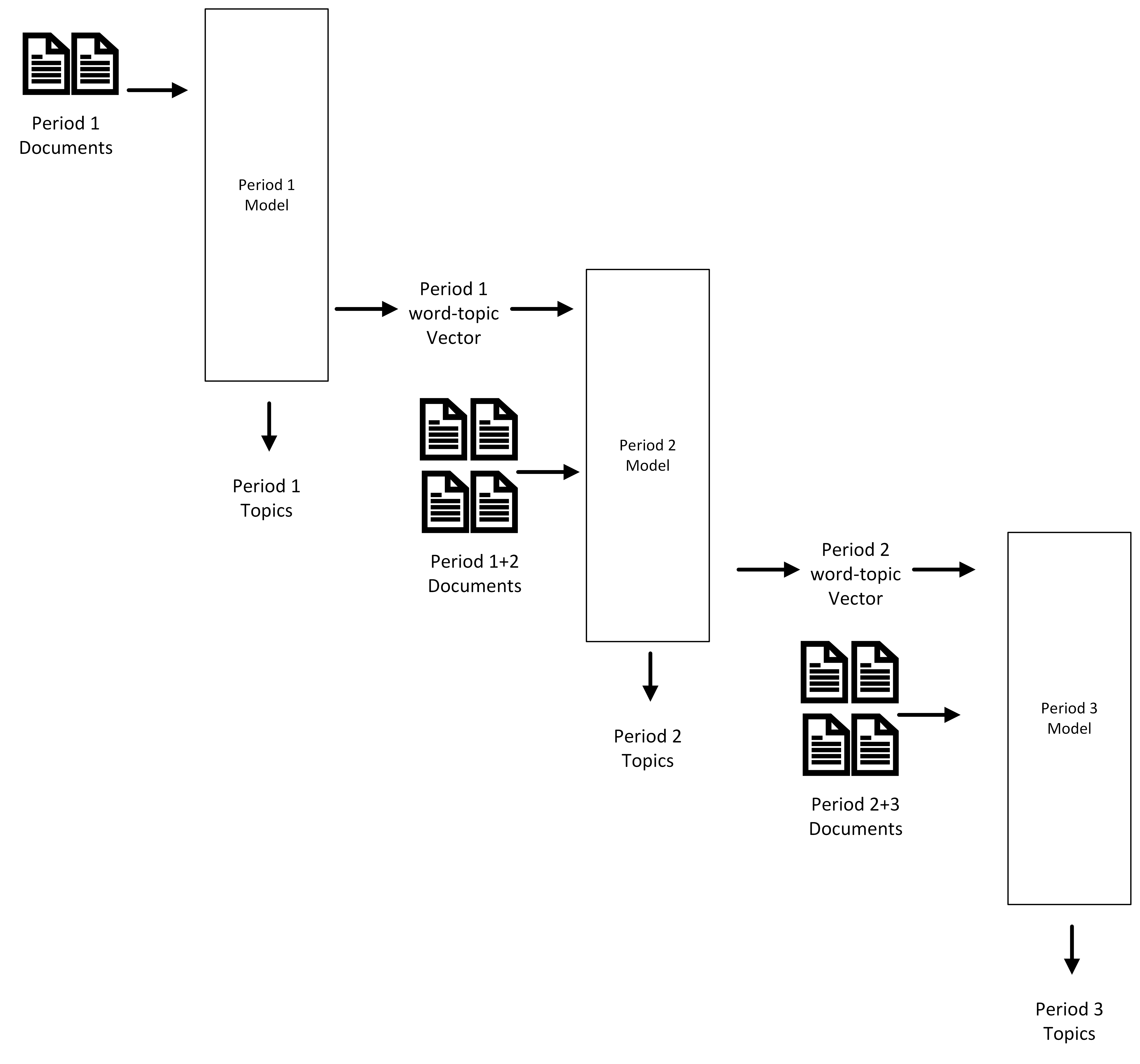
To present our method we consider a dataset with four time periods, each containing one thousand documents. We begin by building a traditional LDA model with the first two time periods of data. We then extract the word-topic matrix of this model that consists of a word-topic vector for each word in the corpus. The word-topic matrix is a Nxk array where N is the number of words in the corpus and k is the number of topics used. A word topic-vector represents how much a given word contributes to a topic.
We now consider the second time period. We apply a sliding window approach; in the new time period we use both time period one and time period two to inform an LDA model. This sliding window enables us to consider a large volume of text over time, and further grounds the topics found by model two with those found by model one as they are still in the data. We then apply the word-topic matrix extracted from model one to the second model as word priors. These priors effectively bias the model toward finding the same topic at the same index. Biasing replaces the randomness in the model initialisation above for the words that have priors to apply. For words that are present in both period 1 and period 2 their initial topic distributions in period 2 will be replaced by the final distributions of words over topics from period 1. Returning to Figure 1 above, this addresses the data linkage problem and makes it more likely that the period 2 outputs correspond to the outputs of period 1. We again extract the word-topic matrix from this model.
Finally, we consider periods 3 and 4. We build a third model informed by period 2 and period 3. We apply the word-topic matrix from the period 2 as a word prior to the third model. By chaining models together using word-topic matrices as word priors, we can expect a few possible scenarios. Firstly, word-topic vectors will converge on any topics that still exist in the subsequent model resulting in a topic having the same index in both models. Secondly, topics that are similar will also maintain index as the word-topic vectors converge on the related distribution. Finally, if a topic is no longer prevalent in the second model, the word-topic distribution will diverge away from the prior and converge on a new topic.
Figure 1: Overview of dynamic topic model, three time periods
Results
For evaluation in this blog we use a publicly available dataset from Kaggle. We take the news data from Kaggle and separate into two overlapping time periods:
- 01/01/2015 to 01/03/2015
- 01/02/2015 to 01/04/2015
Table 2: Topic examples from Kaggle data

Using the example topics and their topic ID above we can identify emerging, receding and evolving topics. Over time we would expect to see topics that recede eventually be replaced by new topics that are more common across the documents. As an example we compare topics five and six. Topic five is evolving, growing in popularity and becoming more general to be about development in industry. Compared to topic six which is persistent in both size and word use.
We also report the CV Coherence for each of the two topic models produced. The CV Coherence is a measure of semantic similarity between words of a topic, it ranges from 0 to 1. Coherence is commonly used to judge the performance of topic models, with higher scores indicating more human-intepretable topics. For the first time period above we report a coherence of 0.618. For the second period we report a coherence of 0.625.
Limitations and future work
The code used for this project along with the example applied to Kaggle data is available on our GitHub. The limitations of the modelling approach are:
- we have not performed benchmarking or analysis of the optimal sliding window size due to the scope of our project having a set sliding window to apply, it is recommended that this window size is optimised based on the number of documents per time period
- experimentation is required between datasets to find the optimal bias vector size, for example applying the entire word-topic vector as biases ensures every word in the period 1 corpus is accounted for but using just 50 words may be preferred to reduce the bias or increase speed
- for our problem an LDA model was sufficient and whilst we experimented with Non-Negative Matrix Factorisation (NMF) we applied the LDA model predominantly due to its ability to handle biases
- applying biases has a risk that words that appear in period 2 were not present in the bias from period 1, in this case these words are placed randomly in space in the second model, so in some cases may not be placed optimally immediately in period 2. This is not a problem when words are not present between period 1 and 2
- when deploying as a process it is recommended that after many biased time periods a new unbiased model is built for comparison or use.
We have presented our work on dynamic topic models for others to use and extend the method. There is room for further exploration with modelling topics through time and we look forward to publishing further experimentations in the future.