
Building tools to generate low fidelity synthetic data

Image Source: Image by Goren Eidens on Unsplash
Building tools to generate synthetic data
The Welsh Government Data Science Unit have used synthetic data to support several projects including the testing of new services and data processes. In this blog we will provide an overview of the code we have developed to quickly generate low fidelity synthetic data. We will also demonstrate its use through an example. The code we present was also used to generate synthetic data for our ADR Wales Report: Scoping and evaluating synthetic data to enhance access to research data
Before talking more about our work, we think it is important to define what we mean by low fidelity synthetic data. We define low fidelity synthetic data as data that mimics a real dataset or data specification without any statistical relationships preserved. This is an important distinction from high fidelity synthetic data that is generated with the goal of preserving to some extent the statistical relationships and patterns from a real dataset. Developers can add extensions to the code, for example, using custom functions or adding weights to randomly generated categories to preserve single variable distributions that may increase the fidelity of the dataset.
Tools available for generating synthetic data
Our code to generate synthetic data uses the faker Python package. This package is capable of generating vast amounts of fake information including names, dates, addresses and job titles. We have also used faker to generate fake information that is structured in locale-specific formats like national insurance numbers and postcodes. For those interested in exploring the faker package in more detail the full documentation is available here.
The faker package provides most of the functionality we need to generate synthetic data. However, there are a few additional motivations we had for incorporating the faker package whilst also adding some of our own functionality:
- A vast amount of public sector data relates to demographic information which tends to be categorical with fixed categories (for example, age bands: 0-9, 10-19 …) therefore we wanted to use sample functions on pre-defined categories rather than generating purely random categories.
- Lots of analysis projects will use linked or relational datasets, the code we have written makes it easy to link synthetic datasets in a consistent way to how the real datasets are linked.
The remainder of this blog will focus on how our code can be used and provide some useful code for doing so.
Practical example of the low fidelity synthetic data code
To use the data code, you will first need to follow the instructions listed in the README file for the repository. This includes cloning the repository and installing the necessary dependencies. The example below begins after cloning the repository and installing dependencies. As an example, we will generate data that matches the following relational schema:
Figure 1: Example schema
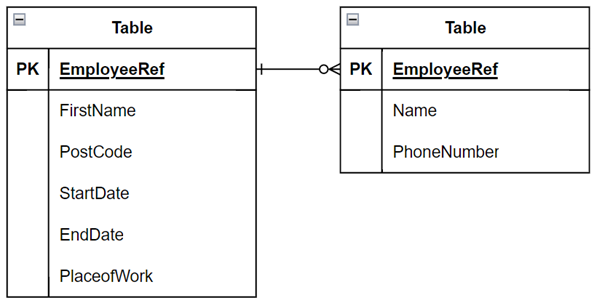
We will be generating two tables. An employee table and a contact information table. There are some constraints in the schema:
- Employee ID must be a primary key
- An employee can have multiple emergency contacts
- Employee ID is a foreign key in the emergency contacts table relating to the Employee ID in the Employee table
We will also add the following logical requirements:
- Employment start date must be after 01/01/2000
- Employment end date must be after employment start date
- Only half of all employees will have an employment end date
- Postcode must be in the UK format
- Place of work will be sampled from a fictional distribution
We first need to set up a JSON file which dictates the structure of our data. For the example, we create the following:
Figure 2: Example JSON file
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
"tables": {
"employee": {
"EmployeeRef": {"type":"id", "prefix":"ORG", "digits": 6, "unique": true},
"FirstName": {"type":"name", "surname":false, "forename":true},
"PostCode": {"type":"location", "level":"postcode"},
"StartDate": {"type":"date", "constraints": [">01-01-2000"]},
"EndDate": {"type":"date", "constraints": [">StartDate"], "null_prop": 0.5},
"PlaceofWork": {"type":"custom", "name":"generate_workplace"},
"__nrows__": 100
},
"emergency_contacts": {
"EmployeeRef": {"type": "foreign-key", "table":"employee", "col":"EmployeeRef", "rel_type":"one-to-many(1)"},
"Name": {"type":"name", "surname":true, "forename":true},
"PhoneNum": {"type":"contact", "level":"phone", "unique":false},
"__nrows__": 150
}
}
}
Some specific items that help us meet the requirements are:
- unique: Ensures that EmployeeRef maintains its integrity as a primary key
- level: Specifies the level at which information is required for the data item, an address for example may be generated at street level or postcode level.
- constraints: Fixed constraints can be given, for example, all dates should be after 01/01/2000 or relative constraints can be given, for example, all employment end dates should be after the employment start dates.
- null_prop: Specifies the likelihood of a value being left null, indicates that a column may contain missing data.
- foreign_key: Specifies that the values should be taken from a primary key in another table.
- rel_type: Specifies the relationship between tables in this case one to many (1) where every employee must have one or more contact.
The JSON file is used to define the structure of the synthetic data. The next step is writing the Python code to generate it. First, we need to write a function that will generate our custom data. We need a generator function, a special type of function that can be used like iterables in Python. Generator functions yield results in a loop which is perfect for our use case of generating synthetic data.
In this case our custom data function is:
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
def generate_workplace(faker):
workplaces = ['Cardiff', 'Powys', 'Conwy', 'Gwynedd', 'Newport', 'Swansea']
weights = [0.2,0.3,0.1,0.2,0.1,0.1]
workplace = np.random.choice(workplaces, 1, p=weights)
yield workplace[0]
custom_funcs = {'generate_workplace':generate_workplace}
which we use to generate a workplace location based on a prescribed distribution defined by the weights list so that there is a 20% chance of employment being in Cardiff, 30% in Powys and so on.
Custom functions enable us to be creative or to adapt to unique requirements when generating synthetic data. For example, we could use custom functions to: • generate custom email addresses that meet an organisation format • generate high-fidelity synthetic data based on a more complex model or on a probability distribution • generate columns that are aggregations or calculations based on other columns
With the custom function defined we are able to generate synthetic data. We start by initialising the generator:
1
generator = DataGenerator('config/example.json', custom_funcs=custom_funcs, seed=2187, locale='en_GB')
When we initialise the generator, we pass in some key information:
- A path to the JSON schema we set up earlier.
- The custom functions dictionary we defined above.
- A random seed to ensure reproducibility.
- A locale (en_GB) which specifies the locale in which to generate information for example generate UK post code formats.
Then we generate the synthetic data:
1
data = generator.build()
Figure 3: Examples of synthetic data
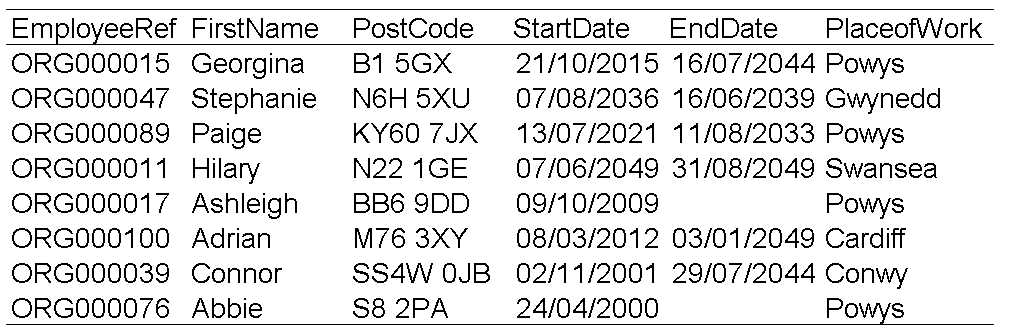
As the examples show we have successfully generated the data to the requirements set out above. The EmployeeRef can successfully be used to link information in the specified relationship type, start and end dates meet the constraints and all information is formatted correctly. This dataset is now ready to be used to test new automated pipelines!
Considerations for reproducibility and accessibility
When generating synthetic data it can be important to consider reproducibility so that the same test data can be used to test a system over many project iterations. Note that above we used random seeds when generating synthetic data. This ensures that using the same schema we can get the same synthetic data in any environment. There is also an added benefit to reproducibility by using JSON schemas as we can catalogue and store the JSON file used to generate a dataset and archive for later use. Further, it is possible to provide a JSON schema and support code to an analyst to generate their own synthetic data based on your specification. This enables users to create as much data as they require.
The synthetic data tool presented is aimed at analysts, data scientists and statisticians with a range of coding experience. Therefore, we consider accessibility to be of high importance. We have implemented the JSON file approach to enable the tool to be used with minimal code to generate simple synthetic datasets. For those with more experience in coding we present the tool as a starting point to extend across more bespoke use cases. This can be done using either the custom functions capability or just the concepts shared in the synthetic data tool.
Considerations for diversity and inclusion
The examples above make use of the locale argument in the faker package to generate data with respect to the en_GB locale. This ensures that addresses and ID information (national insurance numbers) are in the Great British format. However, when generating synthetic data it is important to be mindful of diversity and inclusion especially when using locales. We point to the use of custom functions, or iterative approaches to generation to use multiple locales when generating synthetic data. This ensures that downstream use cases consider diversity and inclusion in the same way that they would for real datasets.
As an example, we provide the code below that samples from a short list of Welsh names when producing a first name field. We first add a line to the JSON file:
1
"WelshName": {"type":"custom", "name":"generate_welsh_name"}
We add the custom function to our code and create the synthetic data generator:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import numpy as np
#create a custom function to select from a list of common Welsh names
def generate_welsh_names(faker):
#this list can be updated
welsh_names = ["Osian", "Harri", "Macsen", "Ffion",
"Eleri", "Cadi", "Emrys"]
#select a name
chosen = np.random.choice(welsh_names, 1)
yield chosen[0]
#set up the custom function with a name from the JSON file
custom_funcs = {"generate_welsh_name":generate_welsh_name}
generator = DataGenerator("config/example.json", seed=2187, locale="en_GB")
The generated data will now include a column called WelshName that contains random names from those specified in the function.