
Dylun: Our Content Design Assistant

Image Source: Image by Christin Hume on Unsplash
An AI supported tool for content design
The Welsh Government publishes a wide range of online content including guidance, announcements, press releases and blogs. As an organisation we are committed to making our content easy to understand, accessible and accurate.
In the Data Science Unit, we have completed experimental work to test how Large Language Models (LLMs) can:
- assist professional content designers
- empower everyone to write clear and accessible content
In this blog we will discuss our initial work and present the results.
Overview
The scope of this work is limited to text-based content and does not consider images, charts or tables. We are aiming to ensure text is consistently styled, easy to understand and accessible. We aim to:
- break down long pieces of content into logical sections with descriptive headings
- transform long paragraphs of text into bullet point lists with an explanatory sentence above
- restructure Frequently Asked Questions
- simplify language and make it easier to find essential information
- ensure that text is written in a similar tone to the wider GOV Wales content
Methods
To develop a proof on concept , we have tested different LLMs including:
- Mistral 7B (Instruct)
- LLAMA 3.1
- LLAMA 2
- Phi3
We experimented with these models using two different approaches:
- In-context learning
- prompt engineering instructions
In context learning, sometimes called few-shot prompting, involves providing an LLM an example of the input and output of a task that has been performed correctly. For this problem we provide:
- an example of content written without content design assistance
- a high quality, publication ready version of the example that has been edited by a content designer
- a new piece of content for the LLM to edit
These help the LLM to see what edits have been made to the example content and then apply them to a new piece of content.
Prompt engineered instructions are developed through a trial-and-error process. We provide a system prompt to the LLM . A system prompt is the prompt provided before content and detailed instructions. They typically consists of:
- a role “You are a professional content designer”
- some basic instructions “You will be provided with content to edit”.
We evaluate the result and update the prompt accordingly to try and get a better designed piece of content next time. Table 1 describes our five prompting approaches.
Table 1: Prompting approaches
| Approach | Name | Description | |
|---|---|---|---|
| 1 | simplify-base | A system prompt that contains excerpts from: https://www.gov.wales/introduction-writing-govwales | |
| 2 | simplify-positive | simplify-base prompt with an extension to ask the LLM to write with a positive, formal or other tone | |
| 3 | simplify-easy-read* | simplify-base prompt with additional guidance on Easy Read text in Table 3 of the paper: https://arxiv.org/html/2407.20046v1 | |
| 4 | full-guidance | Use a large system prompt with the complete Welsh Government Style Guide: https://www.gov.wales/govwales-style-guide | |
| 5 | one-shot | Give the LLM an example piece of content before/after a professional content designer has edited. Ask the LLM to perform similar edits to the new content. |
* Note: We use Easy Read text to identify a type of content primarily designed for and used by people with learning difficulties, text being easy to read is a requirement for all our content.
We rule out approaches four and five based on a qualitative review. Reading the content edited based on these prompts we found:
- the LLMs would get confused and edit the high-quality example or the long guidance rather than the intended content
- some LLMs could not handle the volume of text provided due to their limited context windows
A future project could revisit approach four with few/many-shot simplification and a larger LLM. It is possible that more examples and a larger context window could lead to more consistent results. We did not pursue this because of the financial cost of using larger LLMs. We now focus on prompts 1 (the simplify-base prompt), 2 (simplify-base + positive tone) and 3 (simplify-base + easy read). The base prompt for the LLAMA 3.1 LLM is provided in Figure 1 as an example.
Figure 1: Base prompt example (LLAMA 3.1)
1
2
3
4
5
6
7
8
9
10
11
12
You are a professional content designer and your job is to make text easier to read and accessible for a government website.
You must be concise, accurate and formal.
You must not change the original meaning of the text.
# Instructions
Use shorter words and sentances instead of longer ones.
Use active voice and not passive voice.
Include only one idea per sentence.
Do not include questions.
Break the text into logical sections where each section has a header, introductory sentence and bullet points if appropriate.
Group similar content into the same section.
We tested the prompts for the three approaches across all four LLMs using two example pieces of content. The test compared an original draft with a draft edited by and an LLM and a draft edited by a human content designer. This helped us to understand:
- whether the LLM improved the design and accessibility of the original draft
- whether the LLM improved the design and accessibility to the same extent as a human designer
- where the LLM and human designer made similar and different changes to the content. The metrics we used to make our comparison were:
- Flesch Kincaid Grade Level (FKGL): A metric calculated based on the number of words, syllables and sentences in paragraphs, indicating the simplicity of the text .
- BERT Score: A score for meaning preservation to ensure that content rewritten by an LLM still has the same underlying meaning.
We used these two different metrics due to the difficulty in distilling the quality of a piece of content and accessibility into a single metric. For example, FKGL indicates how readable content is, but writing about more complex topics increases the FKGL due to the words being more complex. Technical and medical guidance for example is more likely to have complex words and terminology so the LLMs could delete all the complicated information from the content and lower the reading age. This would appear to be improvement, if judged by FKGL alone, but may no longer be representative of what the author wanted readers to know. To address this risk, we use the BERT Score metric to understand if the meaning of the content has changed as a result of simplifying the language or removing important information. Some of the other challenges of reading age metrics are covered in detail elsewhere: What.
In addition to the quantitative analysis, we perform a qualitative assessment of the content designed by the LLMs.
- Manual Evaluation: Asking professional content designers and members of our data science team to read and review the edited content.
- LLM Evaluation: Prompting LLMs to comment on the accessibility and accuracy of redrafted content to review it as a critic.
To make LLMs critique content we provide a system prompt to instruct a model to score content for accessibility and readability. This gives us feedback based on what the LLM already knows about content design and is helpful as we iterate and generate many examples which would be a resource challenge if we were to rely on human reviewers.
Combining quantitative assessment of the reading age of content and qualitative assessment with expert content designers, we can accurately evaluate progress toward the aims given in the Overview.
Results
Quantitative assessment (Flesch-Kincaid Grade Level and BERTScore)
The highest performing LLMs are Phi3 and LLAMA 3.1. Phi3 displayed the greatest reduction in FKGL across the examples, but Llama 3.1 better balances the FKGL and BERTScore metrics. This means that LLAMA 3.1 better preserves the meaning of the text whilst also lowering the reading age. In this section we provide all results based on the outputs of LLAMA 3.1. An example piece of content edited by LLAMA 3.1 is given below in Figure 2.
Figure 2: Content before and after, LLAMA 3.1

Figure 3 shows the FKGL metric using the “simplify-base” (Approach 1 ) prompt. In seven out of the eight test cases the rewritten content had a lower reading grade level than the original content, and in 3 out of 8 cases the LLM reduced the reading age to the same or lower extent as the human designer.
Figure 3: Flesch Kincaid Grade Level for the simplify positive tone prompt across eight example pieces of content
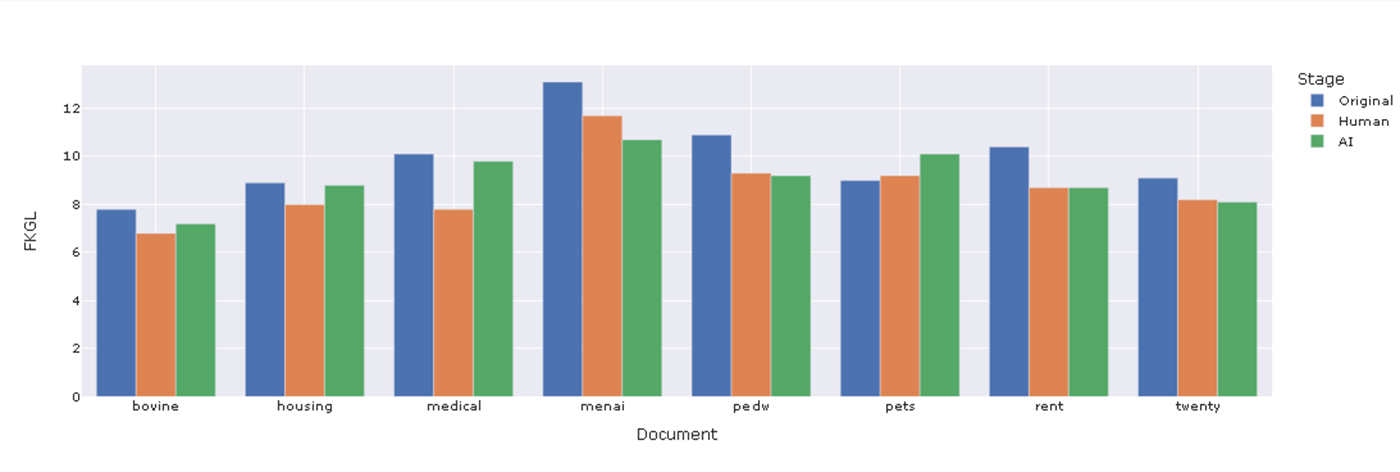
Note: FKGL is reported in terms of American school grades. An FKGL of 8 translates to a UK School Year 9.
Qualitative assessment with LLM critics
When we prompted LLMs to critique the accessibility of our content we found mixed results. For example, in one case when prompted to critique the edited content, the LLM responded with: “The contact information is buried in a list at the end of the content. It would be better to include this information in a separate section, such as a “Contact us” section.” In other cases, the LLM feedback was:
- not constructive - giving no suggestions how to improve
- not comprehensive - finding little or no issues
- out of scope - asking us to consider adding images or diagrams
- not tailored to our style guide - even when provided with a style guide the LLM gets confused on what should be critiqued
Qualitative assessment with human critics
Manual evaluation clarifies the differing goals of the prompts. For example, the quantitative assessment of the “easy-read” prompt (approach 3), results in a less drastic reduction in reading age than approach 1. However, manual review found that this text was edited very well and was much easier to read. An example is given in Figure 4 which shows the LLM over simplifying text but following Easy Read guidance. A noteworthy edit is the replacement of the phrase “silent killer” (paragraph two) with a clear explanation of what this means (bullet one), which is in line with Easy Read guidance to remove expressions and metaphors.
Figure 4: Example easy-read from the LLAMA 3.1, easy-read prompt (approach 2)

Content designers found that the LLM edits were an improvement on readability and design of content. But they thought that the LLM could do better at:
- meeting specific elements of the Welsh Government Style Guide
- restructuring information: some content would benefit from edits to ensure the flow of the content is logical
These limitations, in combination with complex cases such as the “pets” example in Figure 3 which saw the LLM increase the reading age of content, show that LLMs are not a silver bullet to content design. Whilst they are helpful tools in improving accessibility, readability and design the importance of review, further editing and fact checking by professional content designers cannot be understated.
Discussion
We see our work with LLMs for content design as an evidence base to inform future projects that help users without experience in content design get better first drafts of their content. Crucially, our work shows that LLMs could support everyone to produce simpler, easier to read content, regardless of experience in content design. We produce a wide range and high volume of content as an organisation and our content design community is small, so helping everyone to produce higher quality text is important.
We are currently incorporating our work into an assistive tool, named Dylun, that will help overcome some of the limitations we have found by:
- adding feedback from content designers to the prompts we provide to the LLM
- using regular expressions and pattern matching techniques to highlight style guide contradictions
- providing a front-end application for content designers to test and assess the value of the assistant we develop
We will continue to update on this project in and contribute to the conversation about the practical use of Generative AI for a public benefit . There has been substantial research published on sentence simplification , but only a limited amount focussed on accessibility of text . Much of the research on sentence simplification is modelled as a translation problem, replacing text sentence by sentence with a simpler one. Whilst this is a valid approach to solving sentence simplification, it does not consider the wider readability of the content such as in our work.
The latest updates on this work can be found in our webinar hosted by the Centre for Digital Public Services:
For more information on how the Data Science Unit is supporting accessibility elsewhere in the Welsh Government, check out this blog about how we are making charts accessible using R.